


Hey Reader,
In this article, let us learn and know about the most useful and popular Messaging Queue System Apache Kafka, which is used widely in almost every platform of the IT industry. Also, Apache Kafka has a huge demand in and outside of India.
The Contents of the Apache Kafka article include:
Introduction to Apache Kafka
Why Apache Kafka?
What is Apache Kafka?
Components of Apache Kafka
What are Streams?
What are Zookeepers?
Core terminologies of Apache Kafka
Introduction to Apache Kafka
Kafka is an open-source project which was originally developed at LinkedIn and later open-sourced in 2011. Since then it has evolved and established as a popular tool for building real-time data in pipeline systems.
Apache Kafka has now become a boon to Tech industries as it is more secure and sharable for real-time applications. The official Kafka document says it is a distributed application system, which is similar to an enterprise application system.
Why Apache Kafka?
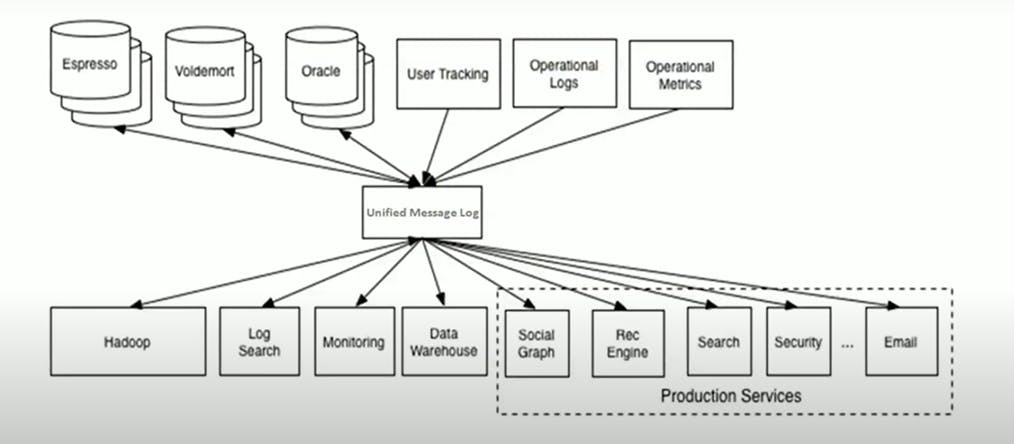
Now, let us understand why Apache Kafka has been introduced to the real world. During the older days, for large enterprise applications, we used to have multiple backend systems where the sender and receivers are huge and it was difficult to identify which particular sender is sending to which resources.

So, if you can observe the above image, the integration part is completely messed up. We can see there are multiple source systems and multiple destination systems. Consider, if you are given a task to create a data pipeline to move data among these systems, in such case some of the pipelines will keep on breaking every day for sure.
But if we use the messaging system for solving this kind of integration problem the solution can be crystal clear as seen in the below image.
And the above idea has been proposed by the LinkedIn team. Then the team started evaluating the existing messaging systems but none of it meet the required criteria.
So, they came up with creating a new Messaging system, Kafka. Let us have a look at the official Kafka diagram.
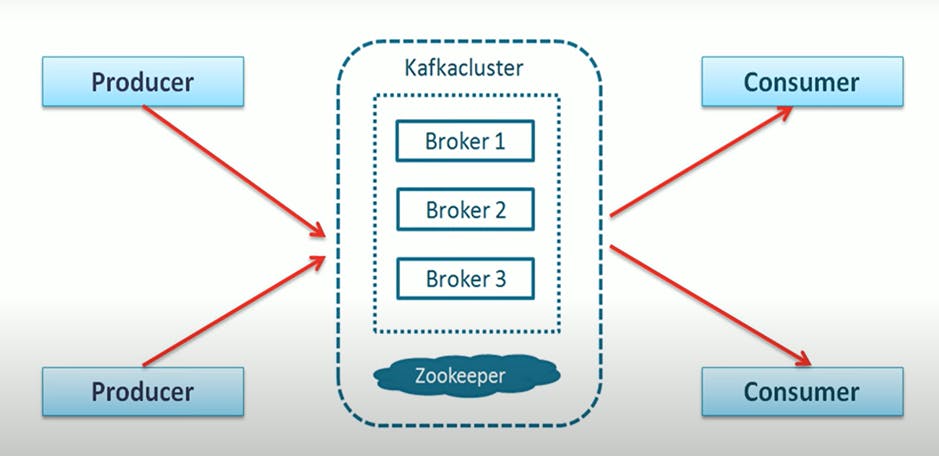
What is Apache Kafka?
Kafka definition can be given as a highly scalable Fault-tolerant, scalable, distributed platform application messaging system.
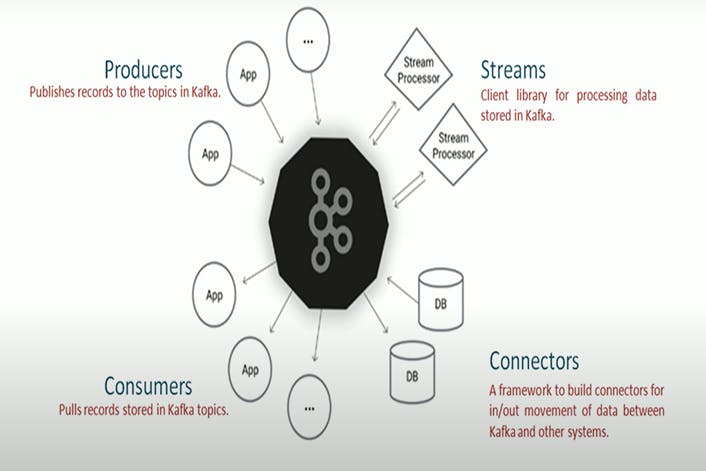
Components of Apache Kafka
In a typical messaging system, there are mainly 3 types of components.
Producer / Publisher - producers are the client application and they send messages.
Broker - The broker receives the message from the publisher and stores the messages in it.
Consumer - Consumers read the message, that they received from the broker.
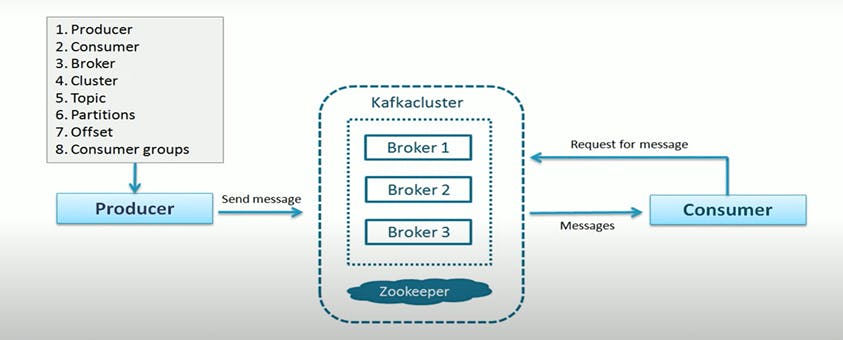
Here, we also use Kafka clusters - Kafka clusters are nothing but a bunch of brokers running in a group of computers.
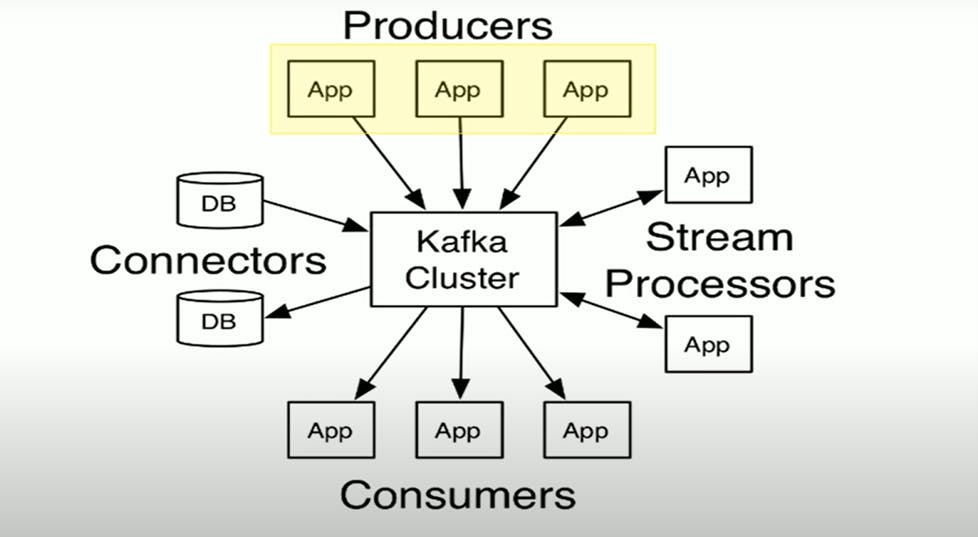
As you can see in the above image, Producers are sending messages to the Kafka Clusters. Here, Kafka clusters take messages from Producers and store them in Kafka message logs.
At the bottom of the image, we can see Consumers, who read Kafka clusters and they use them as per their requirements. They may send it to Hadoop, or Hbase or might send it back to Kafka so someone else can read and modify it.
What are Streams?
Stream is a continuous flow of data, Kafka was developed in such a way that, it can handle the flow of data from the Kafka processor. So it can be stored back into Kafka or can send to other systems.
Kafka also provides Stream processing APIs, these APIs can be used in streaming framework technologies like Spark, Storm and Streaming API.
Core terminologies of Apache Kafka
Producer
Consumer
Broker
Cluster
Topic
Partitions
Offset
Connectors
Consumer Group
Producer :
Producers are an application that sends data or message or record. It can be small to medium size of data. The message which producer sends might be having different meaning or schema to the reader but it is a simple Array of Bytes.

For example, if we want to send a file to Kafka, it will create a producer application and send each line as a message, in this case, the message is one line of text but for Kafka, it is an Array of Bytes.
Similarly, if we want to send all records from a table, it will send each row as a message or we can create a Producer application fire a query against the required database collect the data and start sending each row as a message.
So, while working with Kafka, if you want to send some data, you have to create a Producer Application.
Consumer:
The consumer is again an application that reads or receives data from Kafka, if producers are sending data, Consumes are the recipients.
Remember Producers do not send data, directly to the recipient address. They send it to Kafka Server, so whoever is interested in that data, can use those data, so whichever application request that data will become a Consumer.
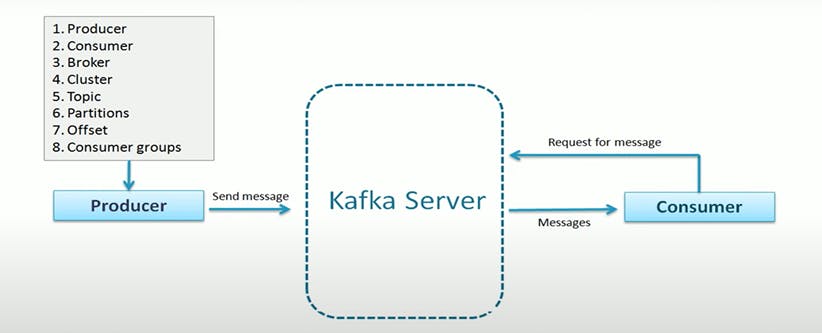
Broker:
Broker is a Kafka server, it is said as a name given to a Kafka server. Because all that Kafka server does is act as a Broker between Producer and Consumer.
Producers and Consumers do not interact directly, they use the Kafka server as an agent or Broker to Exchange messages.
Cluster:
If you have little idea or concept of Distributed systems, you will be knowing what Clusters are. A cluster is a group of computers, acting together for a common purpose.
Since Kafka is a distributed system, so the cluster has the same meaning as Kafka. It is simply a group of computers each executed in one instance of Kafka Broker.
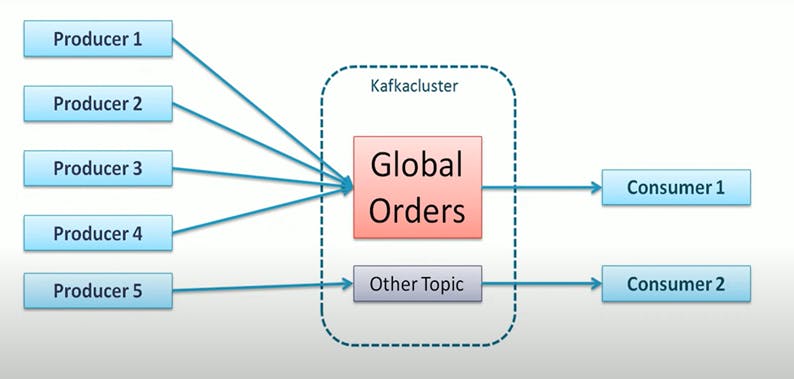
Topic:
The topic is a Unique name given to a data set or Kafka stream.
Example: if we create a topic as Global Orders and every point of sale may have Producers. Each of them sends their order details as a message to a single topic i. e Global Orders. So, the subscribers interested in the order can subscribe to that topic.
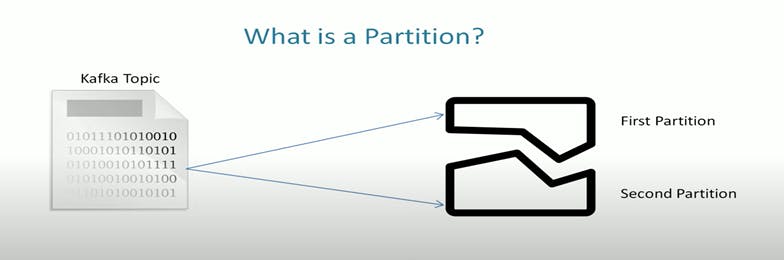
Partitions:
As we know Broker can send data to a Topic, this data can be huge in most cases, and it can be larger than the storage capacity of a single system. In such a case, the broker might have to face challenges in storing such data.
So, one of the solutions could be breaking such huge data into Partitions. The data can be divided into two or more parts and distributed into multiple systems.
Now, the question comes, How many number of partitions can are required?
The answer is Kafka does not decide how many partitions would require, it is the decision to be taken by us.
During the creation of a Topic, we have to decide so Kafka Broker will create that many numbers of Partitions.
Offset:
An offset is a sequence number of messages in a Partition. This number is assigned as the message arrived in the Partition. And these numbers once assigned cannot be changed. They are Immutable.
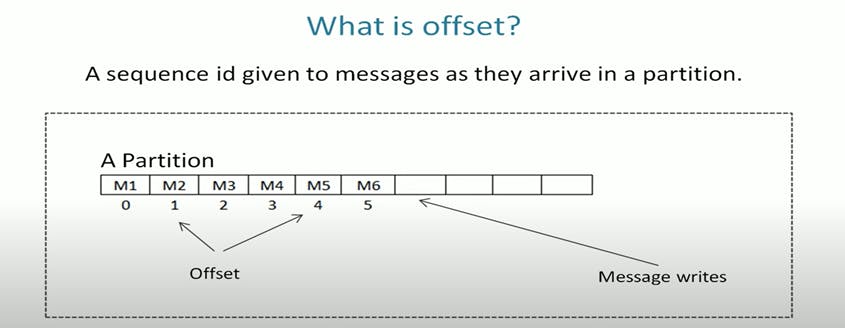
The Sequencing in Offset means that Kafka stores messages in the order of arrival within a Partition and these are local to the Partitions.
Connectors:
Connectors are one of the powerful features, which are like ready to use. Using these we can import data from Database to Kafka or export data from Kafka to Database.
These are not OOTB connectors, but also frameworks to connect to any other applications.
Consumer Group:
A consumer group is a group of Consumers, i.e number of consumers form a group to share the worth. Consider dividing a large work and working on it individually.
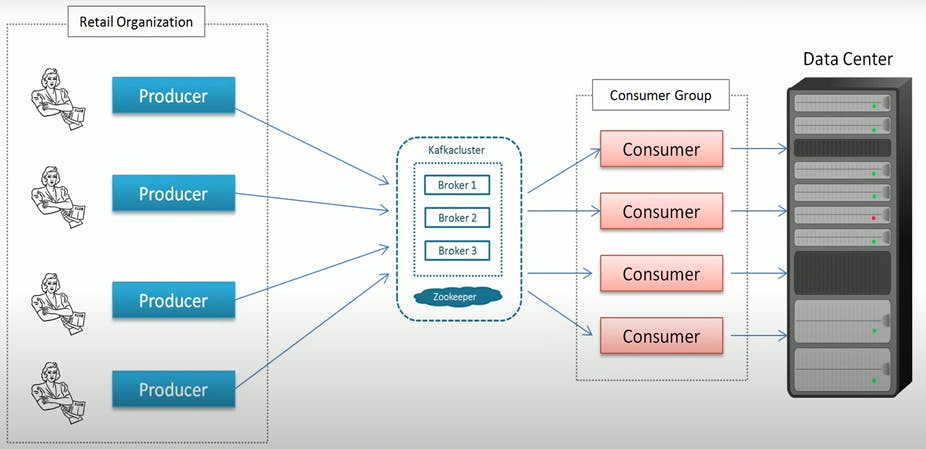
Partition and Consumer Group is a tool for scalability, also the maximum number of Consumers in a Consumer Group is the total number of Partitions you have on the Topic.
These are the basic concepts to be known to go in-depth about Apache Kafka.
Thank you for reading the article. Please like, share and comment. it will encourage me to write more such articles. Do share your valuable suggestions, I appreciate your honest feedback!!!